A young girl is sitting down in a chair.
CLearViD: Curriculum Learning for Video Description
Abstract
Video description entails automatically generating coherent natural language sentences that narrate the content of a given video. We introduce CLearViD, a transformer-based model for video description generation that leverages curriculum learning to accomplish this task. In particular, we investigate two curriculum strategies: (1) progressively exposing the model to more challenging samples by gradually applying a Gaussian noise to the video data, and (2) gradually reducing the capacity of the network through dropout during the training process. These methods enable the model to learn more robust and generalizable features. Moreover, CLearViD leverages the Mish activation function, which provides non-linearity and non-monotonicity and helps alleviate the issue of vanishing gradients. Our extensive experiments and ablation studies demonstrate the effectiveness of the proposed model. The results on two datasets, namely ActivityNet Captions and YouCook2, show that CLearViD significantly outperforms existing state-of-the-art models in terms of both accuracy and diversity metrics. Finally, we discuss the limitations of the current work and outline the future plans.
The girl is strumming the guitar.
The girl pauses for a moment to look at the camera.
A man is seen pushing a lawn mower along the yard while the camera captures him from several angles.
The man then moves the mower along the yard and moves back and fourth.
The man continues to mow the lawn and ends by speaking to the camera.
A woman is seen speaking to the camera while holding up a box and leads into her wrapping paper around.
The two then begin speaking to the camera while showing off how to properly wrap the box.
She continues speaking to the camera while showing off her movements.
A small group of people are seen standing on a beach with one holding a bucket.
The girl then begins digging in the sand.
The girl then begins to build the sand castle.
The girl gets up and walks away.
Method
Our Video Description model uses a mix of:
curriculum learning by noise, curriculum learning by dropout, and Mish activation function.
See the paper for more details.

Curriculum learning by noise.
During the training process, we gradually increase the amount of Gaussian noise applied to the training set.
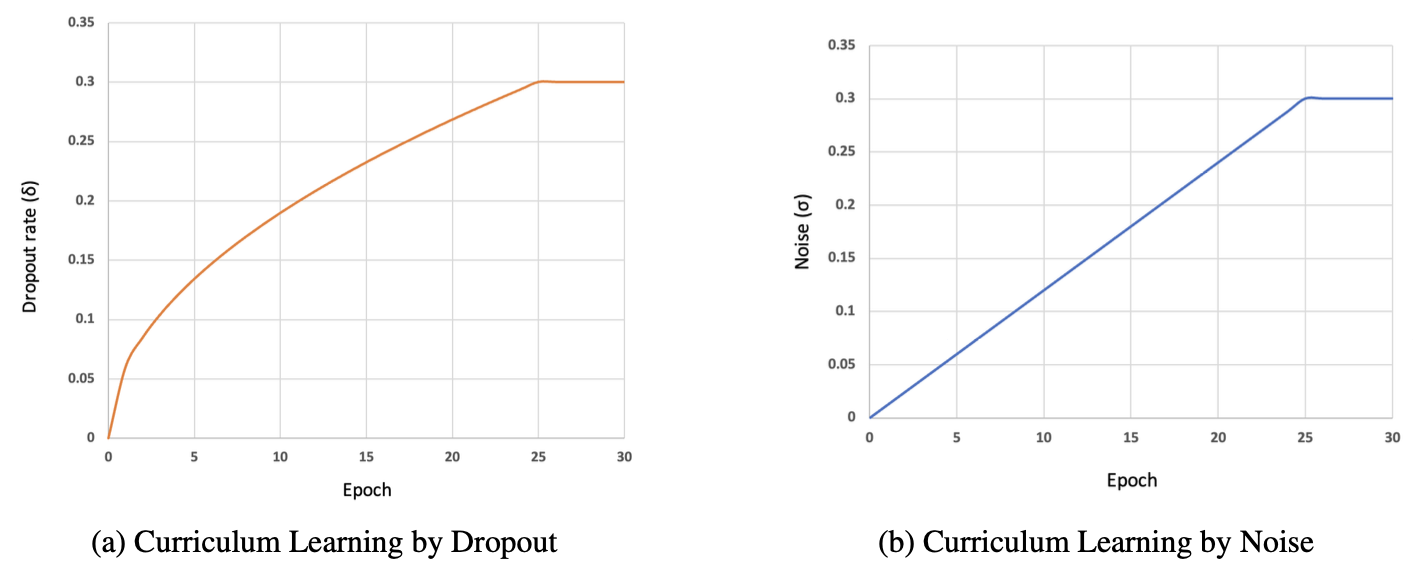
Graphs of (a) the dropout rate, δ in curriculum learning by dropout and (b) the standard deviation (δ) of the Gaussian noise in curriculum learning by noise during the training process.
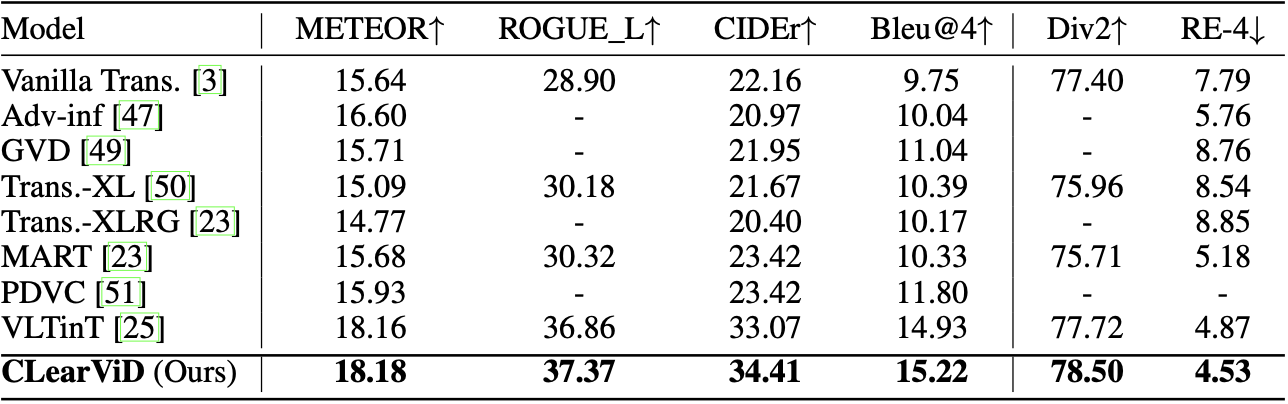
Quantitative Results
Performance comparison of CLearViD with other SOTA models. '-' denotes the paper did not report the score for that particular metric.
See the paper for more analysis.
ActivityNet Captions ae-val
ActivityNet Captions ae-test
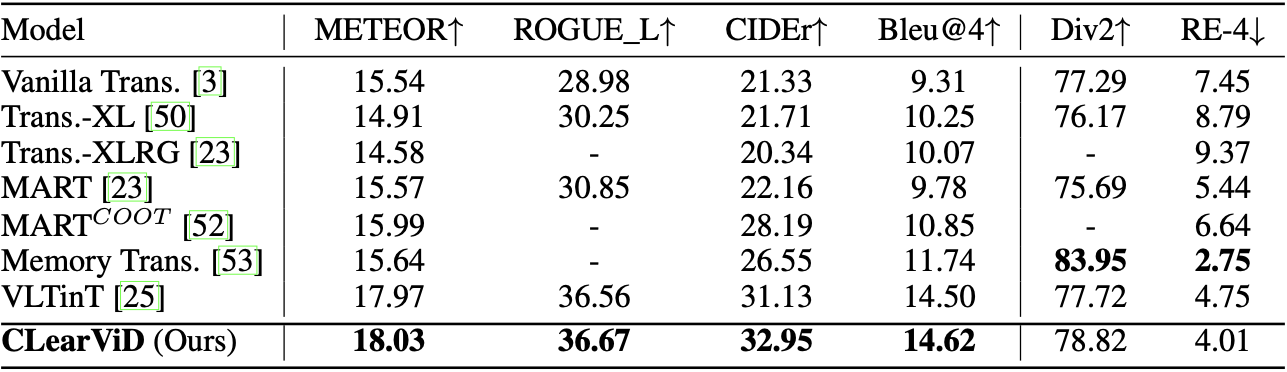
YouCook2

Qualitative Results
Qualitative comparison of the ground truth (GT) descriptions with those generated by the
VLTinT baseline model and our proposed model, CLearViD. The examples are from the ActivityNet
Captions ae-val, ActivityNet Captions ae-test, and YouCook2 datasets. Red italics indicates the
description errors, purple underlining indicates repetitive patterns, and blue bold indicates distinct
expressions.
See the paper for more analysis.
